The following audio examples accompany the submission
J. Ahrens, H. Helmholz, D. Alon, S. Amengual Garí, “Spherical Harmonic Decomposition of a Sound Field Based on Microphones Around the Circumference of a Human Head,” IEEE WASPPA, 2021.
(Update: At the bottom of this page, we provide a video demonstration of a prototype that implements an updated version of the method.)
All audio examples compare a direct auralization of the HRTFs that were used for the rendering of the head-mounted array (i.e. the reference) with the head-mounted array output (the DUT). The parameters with which the signals of the head-mounted array were created correspond to those used to produce Fig. 4-6. I.e., we’re using 18 microphones that are mounted as depicted in the following figure to perform 8th-order rendering:
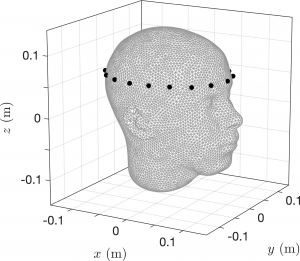
As discussed in the paper, the output of the head-mounted array suffers from an attenuation of the energy at frequencies above approx. 6 kHz, which is straightforward to equalize. We did not do this with the present example so that they may sound a little dull.
In the following, we compare horizontal sound incidence from different azimuths (Fig. 4).
| Azimuth | HRTFs | Head-mounted array |
| 0° | ||
| 45° | ||
| 90° |
The following examples compare sound incidence from azimuth -45° and different elevations (kind of like in Fig. 6). We chose to use sound incidence from lateral directions because these tend to sound a little more spacious than sound incidence from straight ahead is such free-field scenarios. Otherwise, there is no qualitative or quantitative difference to the data in Fig. 6 in the paper.
| Elevation | HRTFs | Head-mounted array |
| 0° | ||
| 30° | ||
| 60° | ||
| 90° |
Note that the head-mounted array produces the correct interaural time difference even for non-horizontal sound incidence.
Here is a video demonstration of a prototype that implements an updated version of the method: